行业观察:DeepSeek V4 技术规格泄露,国产大模型蓄势待发
随着大模型技术的飞速发展,各家厂商新品迭出,而备受瞩目的 DeepSeek V4 预计将在月底发布,其技术规格的提前曝光引发了业界的广泛关注。
DeepSeek V4 的最大亮点在于其可能采用的创新技术,旨在提升国产 AI 大模型在全球舞台上的竞争力,并有望达到与顶尖闭源模型比肩的水平。此次曝光的信息详细展示了这款模型的技术细节,预示着其在参数规模、上下文长度以及底层技术上的重大突破。

据透露,DeepSeek V4 将推出两个版本:完整版拥有高达 1.6 万亿的参数量,而 V4 Lite 则具备 2850 亿参数。这些数字与此前的传闻相符,显示出其在模型规模上的野心。
在核心的注意力机制方面,DeepSeek V4 采用了 DSA2,整合了 DeepSeek V3/R1 中的 DSA 机制以及年初提出的 NSA 稀疏注意力机制,这预示着模型在处理长序列和提升计算效率方面将有显著改进。
MoE(混合专家)模型技术方面,DeepSeek V4 采用了融合方案,配备 Mega 内核,每层拥有 384 个专家,每次激活 6 个专家,这有助于模型在保持高效率的同时,实现更精细化的特征提取。
残差连接设计上,DeepSeek V4 沿用了之前论文中提出的 Hyper-Connections,这一技术在 DeepGemm 的更新中也有提及,有望优化模型的训练稳定性和性能。
在后端训练及优化方面,DeepSeek V4 采用了 Muon 优化器,RL 强化学习则结合了 GRPO 及 KL 散度修正。值得注意的是,模型将预训练的 32K 上下文扩展到了惊人的 1M 上下文长度,这将极大提升模型在处理长文档、复杂推理等场景下的能力。
尽管之前有消息暗示 DeepSeek 系列将支持视觉能力,成为多模态模型,但此次泄露的信息显示,DeepSeek V4 仍是一款纯文本大模型,这一情况略显出乎意料。
此次曝光的信息量巨大,虽然其真实性尚待官方确认,且部分技术细节可能来自公开资料的综合整理,但无疑为 DeepSeek V4 的强大实力提供了窥探的窗口。DeepSeek R1 发布已 15 个月,DeepSeek V3.2 最终版也过去 5 个月,面对当前大模型快速迭代的市场环境,DeepSeek V4 的发布无疑面临着巨大的挑战,其晚于部分竞品发布,也意味着需要通过更强的技术实力来弥补。
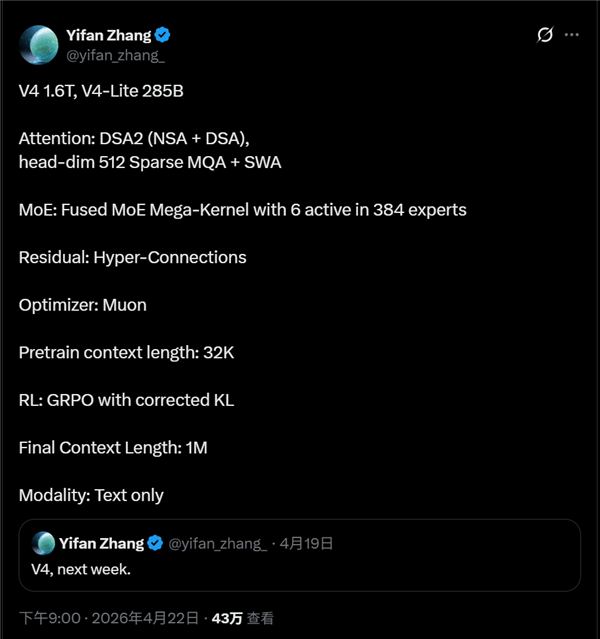
市场普遍期待下周 DeepSeek V4 完整版及 Lite 版能够如期上线,并期待其在技术层面带来更多惊喜,进一步推动国产大模型迈向新高度。
DeepSeek V4 的技术规格预示着国产大模型在参数规模、上下文长度以及底层算法创新上正逐步追赶甚至在某些方面实现超越,这将对全球 AI 竞争格局产生深远影响。