DeepSeek V4:性价比与实战表现的多维度审视
近日,一款名为DeepSeek V4的大型语言模型(LLM)正式上线,其高达1.6万亿的参数量、百万级别的上下文窗口以及极具竞争力的API价格,引发了行业的高度关注。尽管其理论参数令人瞩目,但上线三天后的首批实际测试结果,却呈现出一些出人意料的亮点,尤其是在性价比方面,最经济的版本——V4-Flash,展现了不俗的实力。
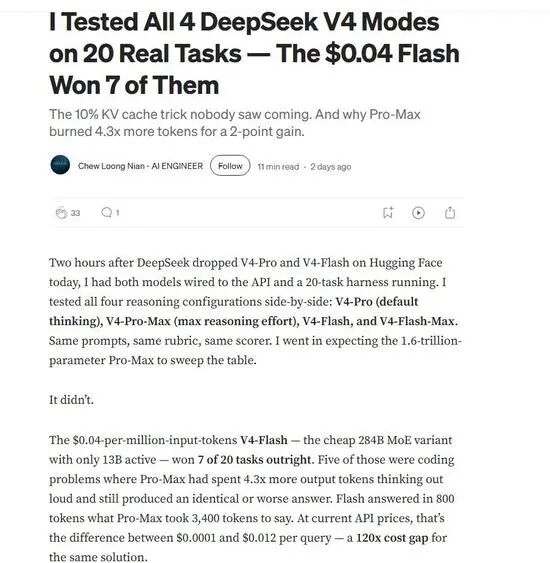
一项涵盖20个真实世界任务的第三方测试显示,DeepSeek V4的四个不同版本(V4-Pro、V4-Pro-Max、V4-Flash、V4-Flash-Max)在实际应用中的表现存在显著差异。其中,最受瞩目的是V4-Flash。该模型在多个编码任务中,以更少的计算资源和更低的成本,取得了与更昂贵的Pro版本相当甚至更优异的结果。例如,在一个特定任务中,Flash版本仅用800个token便完成了问题解决,而Pro-Max版本则耗费了3400个token,成本相差高达约120倍。这表明,在许多实际应用场景下,较低的参数量和更快的响应速度,可能比极致的参数量和深度推理更能高效地达成目标,Flash版本的突出表现,与其在KV缓存压缩技术上的创新不无关系,这为其在低成本下维持高性能奠定了工程基础。
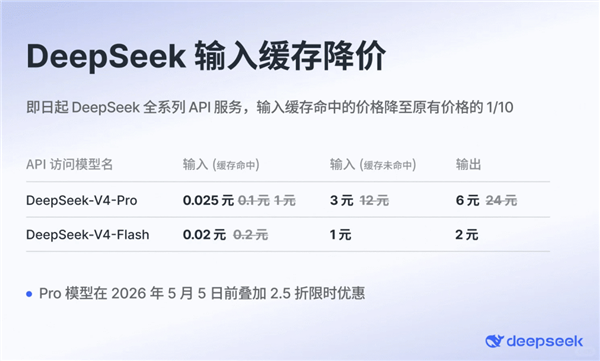
DeepSeek V4-Pro版本则瞄准了当前顶级闭源模型的性能标杆。根据官方及第三方基准测试,V4-Pro在多项关键能力上已能与Anthropic的Claude Opus 4.6、OpenAI的GPT-5.4及谷歌Gemini 3.1等模型相媲美,并在编码、数学和STEM领域展现出强大的优势,成为迄今为止最先进的开源模型之一。然而,在与GPT-5.5和Claude Opus 4.7等顶级模型的综合能力指数对比中,V4-Pro虽略有差距,但其价格优势极为显著。在不考虑折扣的情况下,V4-Pro每百万token输出的成本远低于GPT-5.5和Claude Opus 4.7,尤其是在初期促销折扣下,其价格优势更为惊人。这种“以较低成本提供相当高比例能力”的策略,正以前所未有的力度推动AI应用的商业化进程,DeepSeek V4无疑是这场价格战的发起者。
尽管DeepSeek V4在参数、速度和价格上都带来了极具吸引力的优势,但在面对极其复杂、高风险的实际项目时,其表现仍有提升空间。例如,在需要高度工程落地、精细化前端处理,以及对一次性成功率要求极高的任务中,GPT-5.5和Claude Opus 4.7等模型依然展现出更稳定的性能。这意味着,DeepSeek V4并未实现全面超越,而是将AI模型的竞争焦点从“谁最强”扩展到“谁最适合特定场景”。其开源许可协议和极具竞争力的API定价策略,为开发者提供了极大的灵活性,无论是选择本地部署还是云端服务,都能在成本与性能之间找到最优解。
相关判断维度:部署与应用考量
在评估DeepSeek V4这类新一代大型语言模型时,除了性能和成本,其在实际部署和应用中的表现也至关重要。对于DeepSeek V4的硬件要求,虽然Flash版本因其较小的激活参数量而对硬件要求相对较低,但Pro版本庞大的参数量无疑需要强大的计算资源支撑,尤其是在本地化部署场景下,对GPU显存和计算能力提出了更高要求。功耗与散热是影响大规模部署效率的关键因素,大型模型的运行必然伴随高功耗,其散热解决方案的有效性将直接关系到长期运维成本和稳定性。生态与供应链方面,DeepSeek V4作为一款新的开源模型,其周边工具、社区支持、第三方集成以及潜在的供应链稳定性,都需要时间来检验和构建。一个活跃的开发者社区和成熟的生态系统,将极大促进模型的普及和应用创新。应用场景的落地门槛也是一个重要考量,虽然DeepSeek V4在编码、推理等方面表现出色,但其在特定行业、特定业务流程中的集成难度、数据适配以及微调的复杂性,将决定其能否真正实现商业价值。同时,竞争格局方面,DeepSeek V4的出现,无疑加剧了开源与闭源模型之间的竞争,也促使其他模型提供商在性能和价格上进行调整,预示着AI大模型市场将进入一个更加激烈的价格与价值并存的时代。
DeepSeek V4的上市,为AI大模型市场注入了新的活力,尤其是在性价比方面,Flash版本的突出表现挑战了传统认知。然而,在追求极致性能与成本效益的同时,真实世界的复杂性依然是检验模型能力的重要标尺。
DeepSeek V4 模型在实际应用中的表现与行业展望
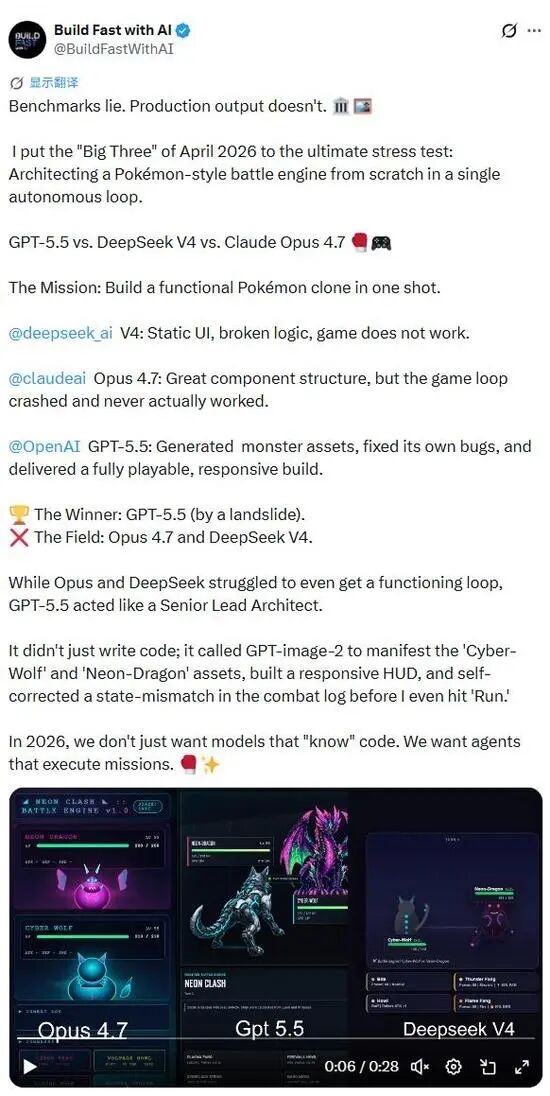
AI 代理能力评估:DeepSeek V4 面临严峻挑战
近期的一系列测试结果揭示了新一代大语言模型在复杂任务执行能力上的差异。在一项模拟游戏开发场景的测试中,GPT-5.5 展示了惊人的自主能力,不仅能够编写代码、生成游戏资源,还能自我修正错误并构建用户界面,其表现被形容为一位资深首席架构师。相比之下,Claude Opus 4.7 在组件结构构建上表现尚可,但未能成功运行整个游戏循环,而 DeepSeek V4 则仅能生成静态界面,且逻辑存在错误,无法运行。Build Fast with AI 指出,当前行业所需已从能懂代码的模型转向能够执行任务的智能代理,它们需要具备自主规划、工具调用、错误修正及成果交付的能力。这表明,在 2026 年,模型的“执行力”将成为衡量其价值的关键指标。
量化交易场景中的实测反馈:DeepSeek V4 的局限性凸显
在更专业的领域,如量化交易,DeepSeek V4 的表现同样受到挑战。一位 AI Agent 开发与测试员分享了使用 V4 进行量化交易的经历。借助 OKX 开源的 agent-trade-kit,测试者得以直接调用交易接口,极大地简化了过去繁琐的基础设施开发工作,将精力聚焦于策略逻辑的描述。尽管 V4 在编写策略代码、分析市场结构及前端界面方面展现了不俗的实力,但实际运行结果却令人失望。模型生成的交易策略在接入真实市场后,面对波动和不可预测的边缘情况时出现了亏损,与纸面上的分析能力形成鲜明对比。这一反馈表明,模型在将策略概念转化为盈利实践方面仍存在明显短板,其在复杂多变的真实世界中的鲁棒性有待提升。
长上下文技术的突破与落地挑战
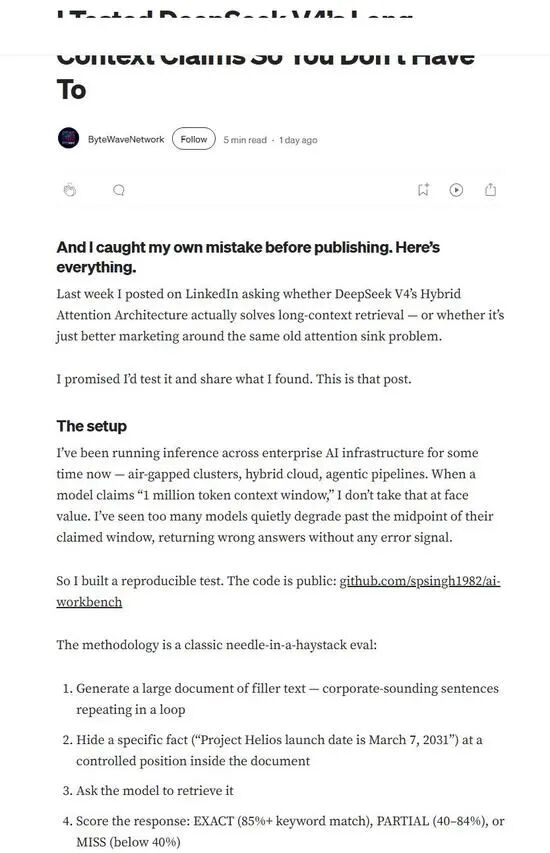
DeepSeek V4 在长上下文处理能力上取得了显著进展,其 100 万 token 的上下文窗口已成为默认配置,与 Gemini 和 Claude 等模型的先进版本处于同一水平。该模型通过创新的混合注意力架构,优化了信息检索效率,显著降低了算力和内存消耗,使得处理海量数据成为可能。实际测试表明,V4 在 100 万 token 上下文检索方面的准确率较高,能够较为可靠地找到隐藏信息。然而,在实际生产环境中,其响应延迟的方差较大,给需要稳定响应的应用带来了不确定性。这说明,即使在技术上实现了突破,长上下文技术的工程落地仍需解决延迟、成本及场景适配等具体问题。
国产化芯片的战略布局与生态演进

DeepSeek V4 的发布也标志着其在摆脱对特定硬件厂商依赖的道路上迈出了重要一步。V4 是 DeepSeek 首款针对华为昇腾等中国国产芯片进行优化的模型,华为昇腾超节点产品也宣布将为 V4 的推理提供全面支持。这为开发者提供了绕开英伟达 CUDA 生态、使用国产硬件部署前沿模型的可能,被视为中国软硬件协同进步的信号。然而,模型训练过程似乎仍主要依赖英伟达芯片,国产芯片主要用于推理环节。这一战略布局旨在利用国内芯片的优势,实现性能与成本的平衡,但也表明在完全实现国产化软硬件协同的道路上仍需持续探索与突破。
DeepSeek V4 的发布,在展示了其在长上下文处理等方面的技术实力之余,也清晰地勾勒出了当前大模型在复杂任务执行、真实世界鲁棒性以及工程落地等方面仍需攻克的难关。模型能力的边界被进一步界定,性价比与最高性能之间存在着明显的权衡,而软硬件协同的战略探索则为行业带来了新的发展方向。
近期,中国AI领域展现出构建自主化基础设施的强大动力,其中DeepSeek V4模型的推出及其与华为昇腾硬件的潜在结合,成为观察这一趋势的重要窗口。虽然昇腾芯片在V4 Flash的部分训练过程中的具体应用仍待证实,但分析人士指出,DeepSeek与华为日益加深的合作预示着昇腾950未来可能在大型模型训练中扮演更重要的角色,这对于对算力要求极高的训练环节而言意义非凡。
DeepSeek官方已将V4模型未来的成本优化与硬件升级紧密联系。公司预计,随着华为昇腾950超节点在大规模出货后,V4-Pro的成本有望显著降低。若此战略得以顺利实施,DeepSeek V4的推出将不仅仅是单一模型迭代,更可能成为中国在自主AI基础设施建设方面取得突破性进展的早期信号。
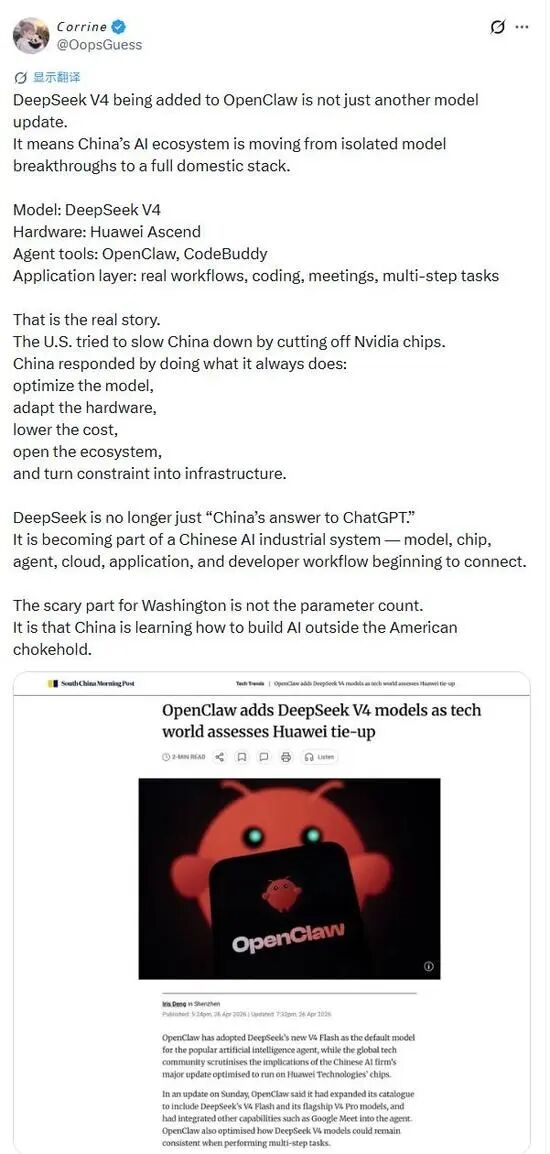
此次DeepSeek V4与OpenClaw等工具的集成,被解读为中国AI生态系统正从过去分散的模型创新,转向构建一个更为完整的本土技术栈。这一战略布局清晰地展示了一个由DeepSeek V4模型、华为昇腾硬件、OpenClaw及腾讯CodeBuddy等代理工具,以及真实编码、会议、多步骤任务等应用场景构成的完整链条正在逐步成形。
在面对外部芯片供应限制的背景下,中国AI产业正通过优化模型、适配自主硬件、降低成本并开放生态系统,将外部压力转化为推动自主化基础设施建设的内在动力。DeepSeek V4的角色正在超越简单的“中国版ChatGPT”,它正成为连接模型、芯片、工具、云服务及开发者工作流的关键节点,推动中国AI产业实现更深层次的互联互通。
行业观察:自主硬件与AI模型的协同发展
DeepSeek V4的崛起,尤其是在其与华为昇腾硬件的潜在协同效应上,为观察中国AI产业自主化进程提供了绝佳的视角。虽然昇腾芯片在模型训练方面的具体贡献尚待进一步数据支持,但训练过程对算力的严苛要求,使得任何可能性的集成都备受瞩目。成本的优化预期,更是将AI模型的性能进步与本土硬件供应链的成熟度直接挂钩,这预示着中国正试图构建一条从底层硬件到上层应用的完整、可控的AI价值链。
DeepSeek V4在长上下文处理、智能体工作流构建以及成本控制方面展现出的实力,为需要处理海量信息和追求性价比的开发者提供了强大的工具。然而,在需要精细审美判断和应对高度不确定复杂环境的首次尝试中,其短板也同样明显。这表明,尽管中国AI产业在构建自主生态上取得了显著进展,但在某些高端应用场景的打磨上,与国际顶尖水平仍存在差距。该模型的推出,更像是重新定义了AI能力的经济学和开放性边界,而非直接挑战现有领导者。
DeepSeek V4并非旨在“统治一切”,而是通过其在成本控制和开放性上的突破,为AI产业的牌桌增添了新的筹码。它证明了在外部限制下,中国AI产业能够通过系统性地构建从芯片到应用的全闭环,实现技术上的自主可控。对华盛顿而言,真正的关注点或许不应仅仅在于模型参数的规模,而在于中国正如何在美国的封锁之外,系统性地构建起一个完整的AI产业生态。