小米发布MiMo-V2.5全链路语音模型,Agent时代语音交互新篇章
近日,小米正式推出了其新一代全链路语音模型系列MiMo-V2.5。该系列模型旨在面向日益兴起的Agent时代,全面提升语音的输入与输出能力,实现语言对语音的自由调度,预示着人机交互方式的重大演进。
MiMo-V2.5系列模型覆盖了语音识别(ASR)与语音合成(TTS)两大核心技术领域。其中,在语音合成方面,MiMo-V2.5-TTS系列推出了面向不同创作需求的三个子模型。
MiMo-V2.5-TTS作为基础模型,内置了多款经过专业调优的高质量音色。这些音色发音自然、情感丰富,并且支持语速、情绪、语气等精细化参数的调整,能够满足多样化的表达需求,实现“开箱即用”的便捷体验。
更具突破性的是MiMo-V2.5-TTS-VoiceDesign模型,它能够仅通过一句自然语言描述,便能生成全新的语音音色,无需任何参考音频。用户可以从年龄、性别、口音、音质甚至性格气质等多个维度进行自由定义,例如“低沉略带嘶哑的老年学者”或“元气满满的少女”,模型即可智能生成与之匹配的声音。这一能力得益于其强大的大规模预训练能力,能够精准理解复杂、模糊乃至矛盾的描述,超越了传统的粗粒度标签限制。
MiMo-V2.5-TTS-VoiceClone模型则专注于音色克隆。该模型仅需用户提供数秒的参考音频,无需额外的训练或微调,即可精准复刻真人声音,包括播客、配音演员、品牌代言人甚至是用户本人。克隆后的声音不仅保留了原始说话者的音色身份,更重要的是,它还能捕捉并保留说话时的气息、节奏以及习惯性的停顿等细微的个人特征。在此基础上,克隆音色还能结合自然语言指令、音频标签或剧本,实现高度自由的语音内容创作。
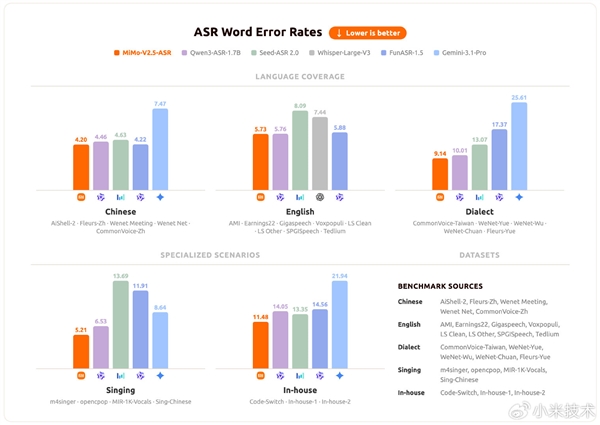
在语音识别方面,MiMo-V2.5-ASR作为整个语音链路的基石,在中英双语、中文方言、Code-Switch(语码转换)、强噪音环境、多说话人场景以及高知识密度内容等复杂真实场景下,均达到了业界领先水平,展现了其强大的鲁棒性和准确性。
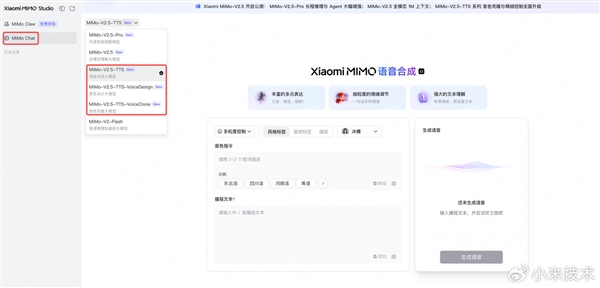
目前,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign以及MiMo-V2.5-TTS-VoiceClone这三款语音合成模型已在Xiaomi MiMo API开放平台提供限时免费体验。

小米此次发布的MiMo-V2.5语音模型系列,不仅在技术上实现了多项突破,特别是在无参考音频的音色生成和精细化音色克隆方面,更重要的是,它为Agent时代的智能化交互奠定了坚实基础。通过“听懂”和“说出”能力的全面升级,预示着未来人机协作将更加自然、高效且富有表现力。