火山引擎近期发布了其豆包大模型家族的首款全模态理解模型——Doubao-Seed-2.0-lite的最新升级版本。此次更新标志着该模型在处理和理解跨多种媒体类型信息方面迈出了重要一步,为企业级应用带来了更强的多模态推理能力。
全模态理解能力全面提升
新版Doubao-Seed-2.0-lite在原生统一理解能力上实现了质的飞跃,能够同时处理视频、图像、音频和文本信息。其Agent、Coding及GUI能力也得到了同步优化,特别是在复杂业务场景下的多模态推理能力得到了显著增强。在视觉理解方面,新模型在物理HiPhO、医疗MedXpertQA等高阶学科推理任务上的表现,已大幅超越今年2月发布的Doubao-Seed-2.0-pro版本。此外,该模型在细粒度感知(BabyVision、WorldVQA)及具身理解(ERQA)等关键领域已达到行业领先水平(SOTA),使其在企业高价值场景的规模化部署中具备显著优势。
音视频深度融合,应对复杂场景
此次升级的一大亮点是语音理解能力的整合。新版本能够同步理解多种输入模态,并进行跨模态的联合推理,直接处理那些需要“音画结合”才能判断的复杂业务需求。例如,在视频理解场景下,Doubao-Seed-2.0-lite能联合分析视频画面与音频信息,精准判断视频中的视听一致性,即“看到的”与“听到的”是否匹配。它还能根据自然语言指令,在视频中精确找到特定事件发生的时间点,并能跨越多个时间段提取关键线索,持续追踪人物与事件发展,通过画面进行多步逻辑推理,还原事件关系与行为脉络。
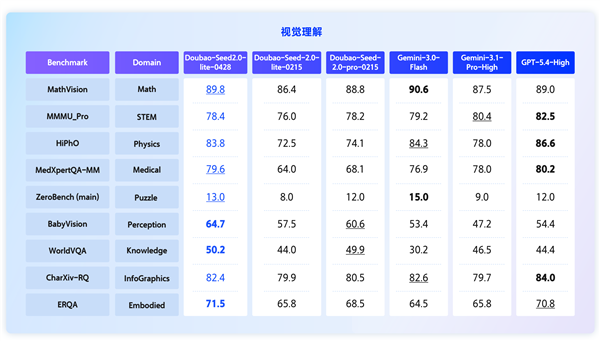
加粗表示最优结果,下划线表示次优结果
语音处理能力增强,性能优于竞品
在音频能力方面,Doubao-Seed-2.0-lite支持19个语种的精准语音转写,以及中英文与其他14个语种的互译。更重要的是,它能够捕捉语音中的情绪变化、环境背景声和音乐细节,输出更完整、更接近人类认知的语义信息。根据公开评测集数据显示,Doubao-Seed-2.0-lite在语音识别、翻译等多项音频理解基准测试中,其表现优于Gemini-3.1-Pro。这意味着该模型在处理多语言音频数据和理解音频细微信息上,具备了更强的竞争力。
Agent框架深度适配,实现持续学习
值得关注的是,Doubao-Seed-2.0-lite深度适配了OpenClaw、Hermes Agent等主流Agent框架,进一步强化了深度搜索与Skill动态调用能力。这种深度集成使得模型在执行任务过程中能够持续积累经验,实现“越用越聪明”的自适应学习。这种持续学习能力对于需要处理动态、复杂业务场景的企业应用而言至关重要,能够帮助企业更高效地解决实际问题,并不断优化解决方案。
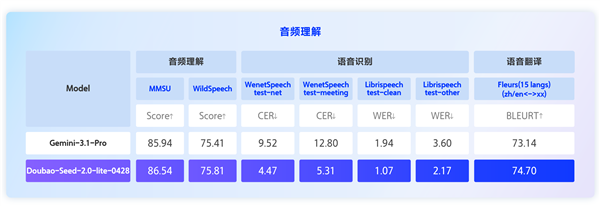

本次Doubao-Seed-2.0-lite的升级,不仅在技术维度上深化了多模态理解和跨模态推理的能力,尤其在音视频的深度融合与精准处理上展现出领先优势,更通过与Agent框架的深度适配,为模型的落地应用和持续进化奠定了坚实基础。这预示着大模型在理解和处理真实世界复杂信息的能力上正不断突破,有望在企业智能化转型中扮演更核心的角色。