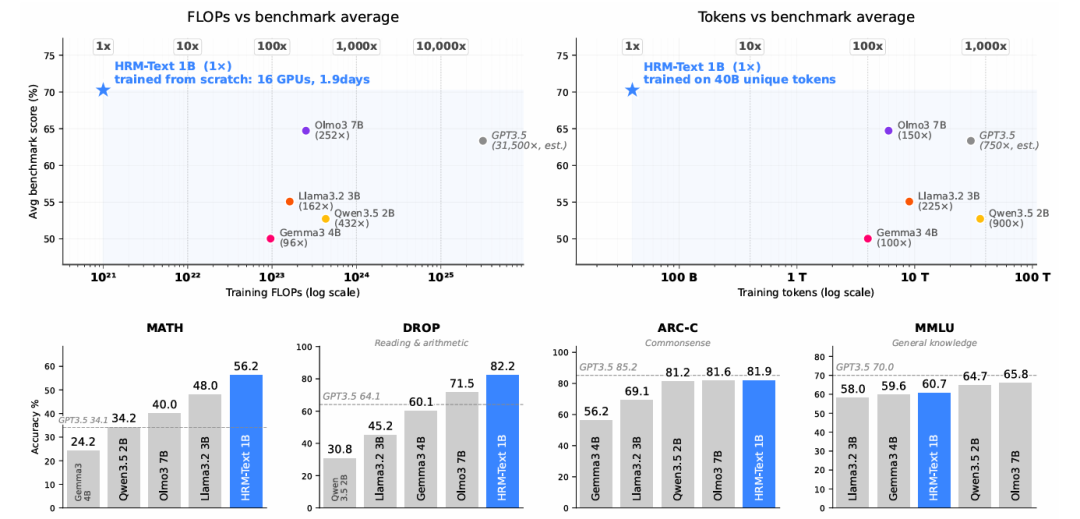
Sapient Intelligence 推出的 HRM-Text 模型,以其约 1B 的参数量,在 MATH 和 GSM8K 等基准测试中取得了令人瞩目的成绩,分别达到 56.2 分和 84.5 分。更令人惊讶的是,其训练成本极低,仅使用 16 块 H100 GPU 运行不到两天,总成本约 1500 美元。这标志着该模型在探索“更高效的预训练”方面迈出了重要一步,直接挑战了当前大模型行业普遍依赖规模扩张的“更大更强”逻辑。
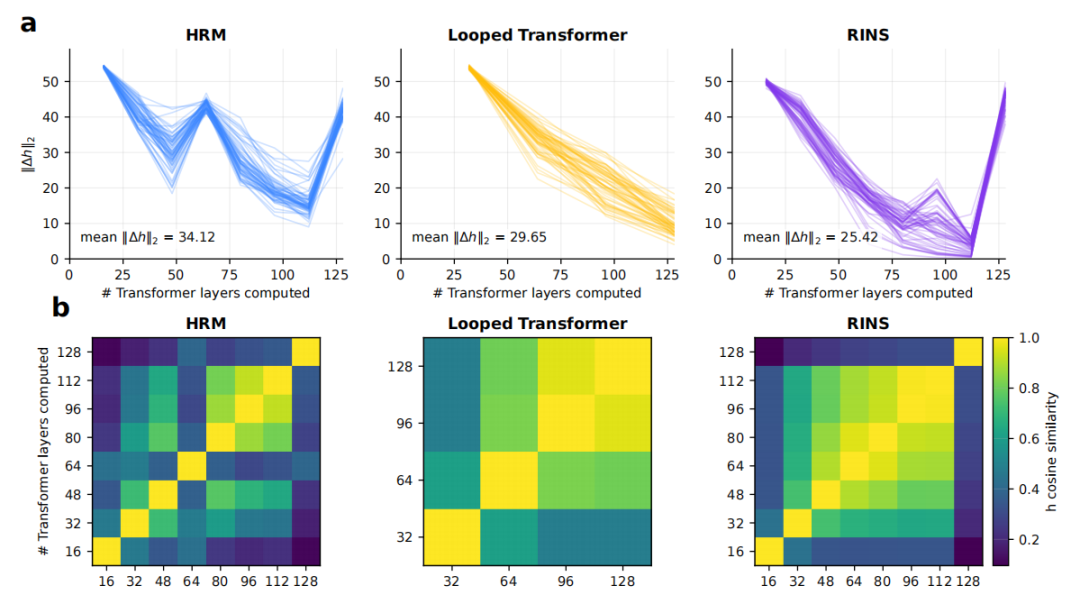
HRM-Text 的创新之处在于其对模型计算方式和训练目标的双重优化。首先,它引入了一种内部多轮迭代的计算机制。不同于传统 Transformer 模型一层层线性处理信息,HRM-Text 将模型划分为高层(H)和低层(L)两个模块,模拟了项目经理和执行人员的协作模式。这种分层设计使得模型在输出最终结果前,能够进行多次内部“思考”和修正,大幅提升了有效计算深度。例如,一个 1B 参数模型在输出一个 token 前,可能经历了高达 8 轮的内部迭代。为了确保训练稳定性,HRM-Text 设计了 MagicNorm 机制来控制激活值累积,并采用渐进式“追责”策略,逐步扩大模型对计算步骤的责任范围。
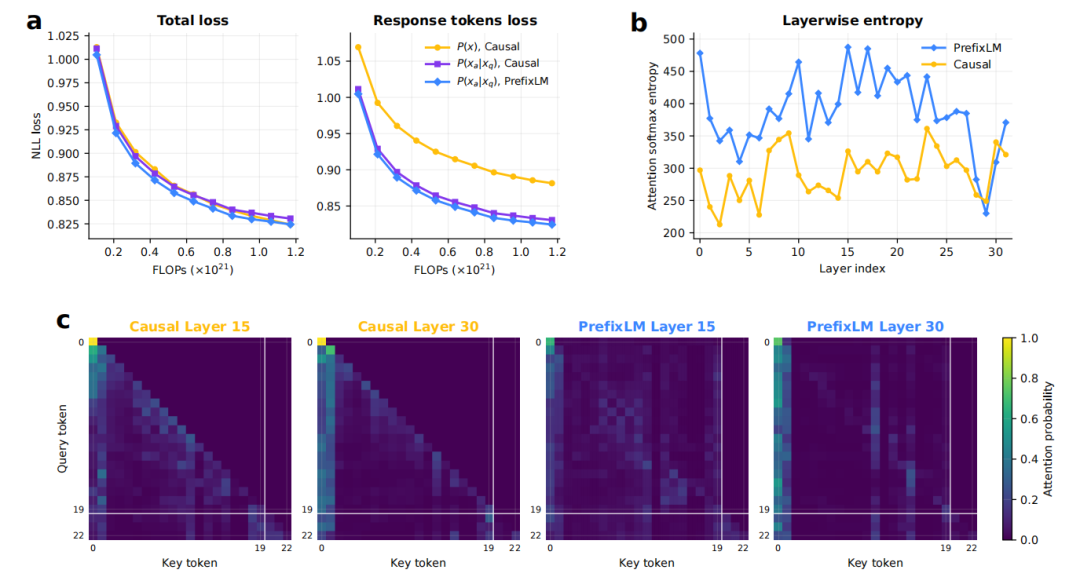
其次,HRM-Text 在训练目标上也进行了重大调整。传统的“下一个 token 预测”模式,迫使模型学习记忆和续写所有文本,导致大量算力被浪费在“背题目”上。HRM-Text 则将计算损失集中在答案部分,即模型只学习如何生成正确的回答,而非预测所有可能的接续。配合 PrefixLM 注意力掩码,指令部分能够相互参考以形成整体理解,而在生成答案时,则切换到标准模式,避免“偷看”未来信息。这种精炼的训练策略,使得模型能够更专注于提升解题能力。
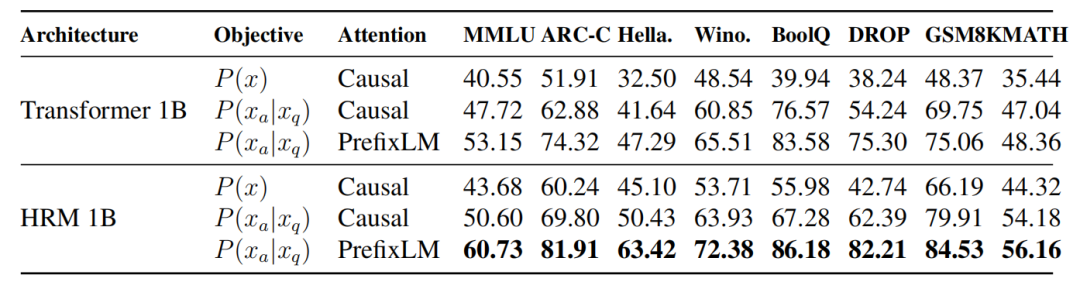
实验数据显示,HRM-Text 的多项优化叠加效果显著。例如,在 ARC-Challenge 测试中,一个标准 1B Transformer 模型得分为 51.91,仅优化训练目标后提升至 62.88,引入 PrefixLM 后达到 74.32,最终采用 HRM 架构后更是飙升至 81.91。这表明其架构和训练方法的协同作用至关重要。HRM-Text 在 MATH、GSM8K 等任务型基准上的优异表现,使其更像是一位“推理专家”。但团队也坦承,有限的数据和参数使其在 MMLU 这类广谱知识测试上不占优势,难以覆盖知识的长尾。未来的发展方向可能包括将这种擅长计算的“小脑”模型与负责知识存储的“大脑”(如检索系统)解耦合作。
HRM-Text 的创新思路已获得学界认可。例如,图灵奖得主 Yoshua Bengio 发布的《Generative Recursive Reasoning》论文中的 GRAM 模型,便借鉴了 HRM 的分层递归路线,并引入了更复杂的概率推理机制,预示着高效预训练模型的研究方向正朝着更具创新性的路径发展。
HRM-Text 的出现,为大模型领域提供了一种新的视角,即通过优化计算和训练策略,可以在有限的资源下实现高效的模型性能。它尤其适合那些对特定推理任务有较高要求的应用场景,展现了小参数模型在特定领域内媲美甚至超越大模型的潜力。
Sapient Intelligence 提出的 HRM-Text 模型,以其仅 1B 参数的体量,在 MATH(56.2 分)和 GSM8K(84.5 分)两项数学推理基准测试中取得了令人瞩目的成绩,其表现已接近 7B 参数模型。尤为关键的是,这一从零开始的预训练过程,仅耗费约 1500 美元、使用了 16 块 NVIDIA Tesla H100 GPU 不到两天的时间,显著颠覆了当前大模型领域普遍遵循的“参数越大越强”的规模定律。
HRM-Text 的创新之处在于,它并未选择通过单纯增加模型规模来提升性能,而是聚焦于优化模型的“思考”与“学习”方式。具体而言,它引入了一种新颖的内部计算机制,将模型划分为高层规划模块(H)和低层执行模块(L),通过多轮内部迭代修正来提升计算深度,使得有限参数的计算效率得到极大挖掘。同时,为了应对循环计算带来的稳定性挑战,模型采用了 MagicNorm 归一化技术和渐进式“追责”策略,确保训练过程的稳定进行。
在训练目标上,HRM-Text 放弃了传统的“下一个 token 预测”模式,转而专注于只计算答案部分的损失,要求模型直接学习生成最终答案,而非“背诵”训练数据。这种策略旨在避免算力被消耗在无效的文本序列预测上,从而更高效地实现智能目标。然而,这种高度内循环的设计也带来了更高的推理成本,并且在向更大规模扩展时,其稳定性问题可能面临更严峻的考验。
评测维度:模型效率与架构创新
HRM-Text 的出现,为大模型的研究与开发开辟了新的思路,即“变巧”而非仅仅“变大”。其在极低的训练成本下,实现了对数学推理等复杂任务的优秀表现,有力证明了在算力与数据有限的情况下,通过精妙的架构设计和训练策略,同样能够实现高效能的模型。这对于资源有限的研究机构或希望降低大模型部署成本的企业来说,具有重要的借鉴意义。然而,其独特的内部循环机制在推理阶段的算力消耗以及模型在更广泛、更开放场景下的泛化能力,仍是未来需要持续关注和验证的关键点。
HRM-Text 的核心贡献在于挑战了行业对模型增长路径的固有认知。它提供了一种在成本、效率与性能之间取得平衡的可能性。虽然其专注于特定领域(如数学推理)的表现抢眼,但其“变巧”的理念和技术,预示着下一代人工智能的发展,或许将更多地体现在模型如何更深层、更智慧地进行计算,而非仅仅堆砌参数。
HRM-Text:以“巧思”挑战“规模定律”,小参数模型能否比肩巨头?
在人工智能领域,参数规模往往与能力划等号。然而,Sapient Intelligence提出的HRM-Text模型,以仅约10亿参数的体量,在MATH基准测试中斩获56.2分,并在GSM8K上达到84.5分,其表现已逼近不少拥有数亿乃至数十亿参数的模型。更令人瞩目的是,这一成就并非通过微调实现,而是从零开始预训练。训练过程仅耗费16块NVIDIA H100 GPU不到两天的算力,成本约1500美元,这无疑是对当前“越大越好”的规模化发展趋势的有力挑战。
HRM-Text 的核心创新在于其对Transformer架构的重新设计,尤其是在注意力机制和训练目标上进行了优化。通过采用PrefixLM注意力掩码,指令部分能够相互“看见”,从而实现整体理解,而在答案生成阶段则切换回标准的单向生成模式,避免了信息泄露。这种设计旨在让模型更专注于解决问题,而不是仅仅进行泛泛的知识填充。消融实验结果显示,仅改变训练目标(如仅预测回答)已能显著提升模型性能,而PrefixLM的引入和HRM架构的采用,更是将ARC-Challenge等任务的得分从51.91提升至81.91,证明了这些改动的协同效应。
这种“专注解题”的设计思路,使得HRM-Text在MATH、GSM8K等任务型基准上表现突出,但其在MMLU这类需要广谱知识覆盖的测试中并未展现出领先优势。团队坦承,有限的数据和参数限制了其知识长尾的覆盖能力。这意味着HRM-Text更像是一位“推理专家”,而非“全知全能的百科全书”。未来的发展方向可能在于解耦其擅长计算的“小脑”与负责知识存储的“大脑”(如检索系统或记忆模块),实现更高效的协同工作。
HRM-Text 所展现的技术路线已引起业界的广泛关注,图灵奖得主Yoshua Bengio团队发布的GRAM模型,也沿着HRM的分层递归思路,并引入了更复杂的概率推理机制。尽管HRM-Text并非完美的解决方案,其推理成本相对较高,且大规模扩展时面临稳定性挑战,但它有力地证明了除了“变大”,模型还可以通过“变巧”来提升能力。这种“巧思”的可能性,在一个深受规模定律影响的行业中,预示着新的发展方向:下一代人工智能的进步,或许不仅仅源于参数和数据的增长,更在于对模型“思考方式”的根本性重塑。
HRM-Text 的出现,为AI模型发展注入了新的思考维度。其核心在于通过架构和训练策略的创新,在有限的参数下实现高效的推理能力,特别是在数学和逻辑推理等领域展现出强劲实力。然而,受限于参数规模,其知识覆盖的广度有所不足,更适合作为特定任务的“专精型”模型。对于需要强大计算和推理能力,但对知识广度要求不那么极致的应用场景,HRM-Text 提供了极具吸引力的成本效益选项。未来,若能有效结合外部知识库,其潜力将得到进一步释放。