在人工智能领域爆炸式增长的当下,算力需求已成为核心驱动力,而GPU作为关键的算力基础设施,正成为科技巨头们竞相投入的焦点。英伟达凭借其在AI芯片领域的领先地位,已成为这一轮技术浪潮中的关键“卖铲人”,其AI显卡的高毛利率也反映了市场对其技术和产品的强劲需求。
Blackwell架构性能跃升,大幅降低AI推理成本
面对市场对AI算力成本的持续关注,以及谷歌、亚马逊、微软等头部企业在自研芯片上的投入,英伟达正通过数据来证明其最新一代GPU的价值。其最新发布的Blackwell架构(以GB300 NVL72为例)与上一代的Hopper架构(以H200为例)相比,虽然在部署成本上出现了翻倍增长(从每小时1.41美元升至2.65美元),但其每美元性能的提升也达到了同等水平,这意味着单位成本下能实现更高的算力输出。
Token生成效率实现跨越式提升
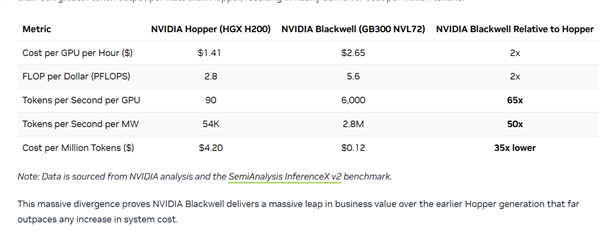
在AI模型推理的关键指标——Token生成速度上,Blackwell架构展现出惊人的优势。数据显示,GB300的Token生成速度达到每秒6000,而H200仅为每秒90,差距高达65倍。在功耗效率方面,每兆瓦(MW)下GB300可生成2800万(28M)Tokens,而H200仅为54000(54K)Tokens,差距同样显著,达到50倍。综合来看,Blackwell架构下的每百万Token处理成本比H200低约35倍,这为大规模AI应用的部署提供了更具经济效益的解决方案。
技术革新驱动性能飞跃

英伟达此次对比的优势,部分得益于Blackwell架构引入的先进技术,例如对NVFP4算子的支持以及MTP(多Token预测)技术。这些新增功能带来了显著的性能提升,也使得新一代产品在与上一代产品的比较中,展现出更为突出的性能优势。正如在游戏显卡领域,英伟达也常通过DLSS等技术来大幅提升游戏性能表现,而新一代显卡内置的先进技术,也理应被纳入其性能评估体系中。
Blackwell架构的推出,不仅在绝对性能上实现了质的飞跃,更在能效比和单位成本效益上带来了革命性的改变。对于那些需要处理海量数据、进行复杂AI模型训练和推理的科技企业而言,选择Blackwell架构的GPU,意味着在长远的运营成本上将获得显著的节约,有助于推动AI技术的更广泛落地和应用场景的拓展。未来,随着AI应用的深化,对高效、低成本算力的需求将持续增长,英伟达在这一领域的竞争优势有望进一步巩固。