在过去的一年多时间里,全球人工智能领域经历了飞速的发展和激烈的竞争。备受瞩目的 DeepSeek V4 模型于近日正式发布,距其前代 R1 的推出已时隔15个月。此次更新备受期待,尤其是在 AI 编程和智能体(Agent)等当前最热门的应用方向上,业界希望 DeepSeek V4 能够与顶级 AI 模型一较高下。
DeepSeek 官方在发布说明中强调,V4 模型在智能体能力方面相比前代 DeepSeek-V4-Pro 得到了显著增强。在 Agentic Coding 评测中,V4-Pro 展现出了当前开源模型中的最佳水平,并在其他智能体相关的评测中均有优异表现。
据内部评测反馈,DeepSeek-V4 已被公司内部员工用作 Agentic Coding 模型。其使用体验被认为优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式,但与 Opus 4.6 的思考模式相比仍存在一定差距。
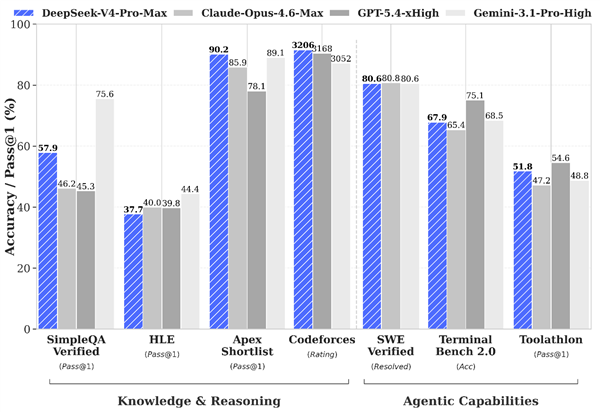
除了官方的评测结果,社区和第三方排行榜也陆续公布了 DeepSeek V4 的实际测试数据,为我们提供了更全面的性能视角。需要注意的是,由于 DeepSeek V4 不支持多模态,因此在涉及图像和视觉的评测中无法进行直接对比。
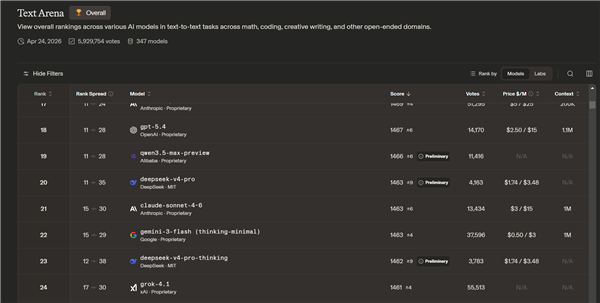
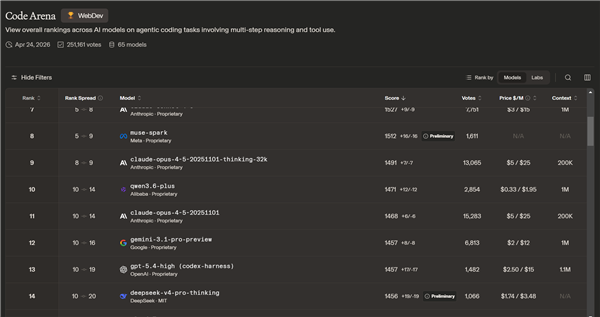
在 arena.ai 的榜单中,DeepSeek V4 在文本能力方面位列第20名,开启“thinking”模式后排名略有下降。在编程能力方面,V4 位列第14名。对比之下,国内在此领域表现最强的 GLM-5.1 位列第5名。
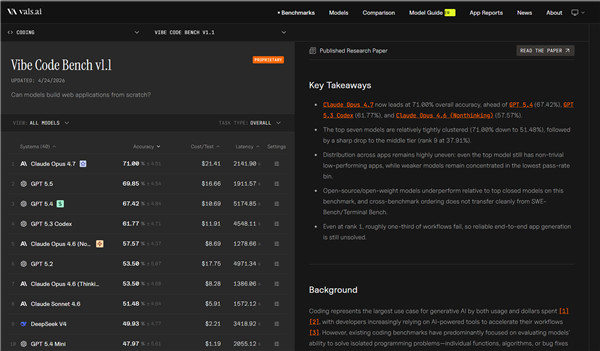
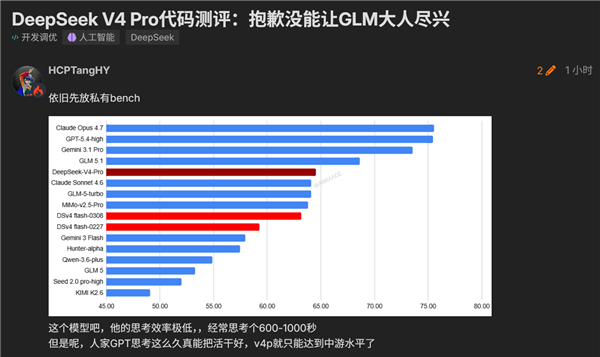
在 vals.ai 的榜单中,DeepSeek V4 被评为开源模型第一,全球排名第九。然而,从分数上看,与榜单前三名模型仍存在较大差距。
此外,在 Linux.do 社区的一些独立评测中,V4 Pro 的表现甚至略逊于 GLM-5.1,与顶尖模型仍有明显差距。综合来看,DeepSeek-V4 在编程能力上较前代有所提升,表现优于 Sonnet 4.5,接近 Opus 4.6 的非思考模式,但与 Opus 4.6 的思考模式之间尚存距离。
总体而言,DeepSeek-V4 在 AI 编程方面的进步是显著的,但尚未达到令人惊喜的突破。与行业领先的“御三家”模型相比,仍有较大的追赶空间。虽然 V4 Pro 的价格相较于“御三家”有所优势,但其总体成本并不低廉,而 Flash 版本则保持了其性价比优势。
过去15个月,DeepSeek 在发展过程中面临着巨大的挑战,包括来自国际制裁和算力资源上的限制,与“御三家”在算力方面存在显著差距。同时,DeepSeek 还肩负着适配国产 AI 算力的重任,这无疑对他们的开发进度带来了影响。
DeepSeek-V4 的发布标志着其在技术上的一个重要节点。然而,在这15个月里,无论是在美国还是国内,AI 领域都取得了飞跃式的发展,Kimi、GLM、MiniMax 等公司均进行了多轮产品迭代。这些竞争对手往往拥有雄厚的资源或强大的融资支持,这对 DeepSeek 来说构成了不小的压力。
目前,只能期待 DeepSeek 能够持续优化,并在解决算力和成本问题后,在未来的版本迭代中展现出更强大的能力。同时,我们也希望下一代 DeepSeek-V5 能够加速问世,避免过长的研发周期。
DeepSeek V4 的发布虽然在编程和智能体能力上取得了进步,但与行业顶尖水平相比仍有差距,尤其是在多模态和全面通用性方面。面对快速迭代的竞争环境,DeepSeek 需要在算力、成本以及产品快速迭代上付出更多努力,才能在激烈的市场竞争中获得优势。