在人工智能训练领域,网络通信的瓶颈一直是制约算力规模化扩展的难题。近日,OpenAI牵头,联合AMD、NVIDIA、Intel、微软和博通等行业巨头,历时两年共同研发的MRC(多路径可靠连接)协议正式对外发布。该协议旨在从根本上解决大规模AI训练过程中,GPU之间因网络通信延迟和不稳定而产生的效率损失问题。
MRC协议的核心在于优化数据传输路径。它将单条高速800Gb/s网络接口,拆分成多条独立的、更小带宽的并行链路。例如,一个接口可以连接到8台不同的交换机,形成8条100Gb/s的独立网络路径。这样的设计能够有效规避单一网络链路因拥塞或故障导致的训练中断,显著提升大规模AI集群的稳定性和数据传输效率。
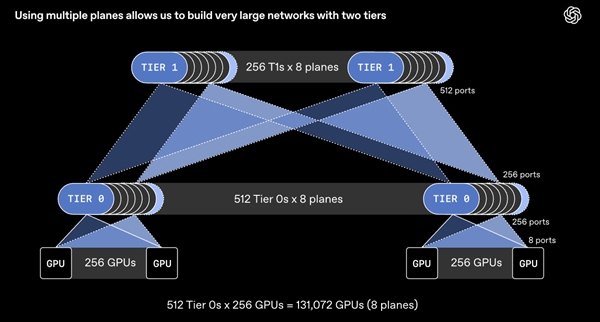
这一创新在网络拓扑设计上带来了颠覆性变化。一个支持64个800 Gb/s端口的交换机,在MRC架构下,理论上可以连接多达512个100 Gb/s端口。这使得仅需两层交换机即可构建支持约13.1万块GPU的全互联网络。相较于传统需要三到四层交换机的方案,MRC显著减少了网络层级,从而大幅降低了数据传输延迟,并减少了潜在的故障点。
MRC协议基于现有的RDMA over RoCE(融合以太网)协议进行扩展,并集成了GPU和CPU的硬件加速功能,以支持高效的远程直接内存访问。目前,该协议已在Oracle Cloud Infrastructure和微软Fairwater超算集群中的NVIDIA GB200 GPU上成功部署,并已用于训练前沿AI模型。OpenAI规划中的Stargate超算项目,目标在2029年实现10GW的AI算力,MRC也将成为其核心网络架构。


MRC协议的开放性预示着AI基础设施领域正走向更加协同的未来。通过将这一关键网络技术向整个行业开放,OpenAI期望推动更多企业和研究机构共同攻克AI算力基础设施面临的挑战。尤其在AI硬件层面,MRC协议对提升GPU集群的互联互通效率和稳定性有着直接作用,进一步为AI模型的训练和推理提供了坚实的基础。该协议的推广应用,将有助于降低大规模AI训练的门槛,并加速AI技术的落地和普及。
此次多巨头联合发布的MRC协议,是AI基础设施领域一次重要的技术突破,它不仅解决了大规模AI训练的网络瓶颈,更展现了行业协作解决共性难题的决心和力量。未来,更高效、更稳定的AI网络架构将为AI技术的飞速发展提供强大的算力支撑。