DeepSeek-V4重磅发布:百万上下文引领行业新标准,AI能力边界再拓宽
今日,深度求索(DeepSeek)正式对外披露了其全新系列模型DeepSeek-V4的预览版本,并同步开启开源及API服务。据悉,DeepSeek-V4在超长上下文处理能力上实现了突破,高达百万字(1M token)的上下文窗口,在Agent能力、世界知识和推理性能方面均展现出国内及开源领域的领先水平。深度求索方面表示,此举标志着“迈入百万上下文普惠时代”。
自2025年初以来,深度求索(DeepSeek)已成为科技圈备受瞩目的焦点。尽管市场曾一度预测DeepSeek-V4将在春节前后亮相,引发行业内高度关注和对大模型领域竞争加剧的讨论,但直到今日,这款旗舰模型才正式面向公众。
“任何一家厂商面对DeepSeek的新进展,都会感受到一定的压力。”一位长期服务于国内多家大模型厂商及互联网巨头的AI产业链人士如此评价。
此前,通过对DeepSeek模型与多款国产大模型进行协同应用的研究发现,国内不少垂直领域平台及场景在成本与效率方面取得了显著兼顾。因此,市场对DeepSeek下一代旗舰模型的期待尤为高涨,其中,DeepSeek-V4在上下文长度、Agent能力、推理成本、AI编程及多模态能力、模型参数维度等方面的表现,更是成为行业关注的重点。
DeepSeek新篇章:百万上下文成为标配
深度求索方面介绍,DeepSeek-V4模型系列包含了DeepSeek-V4-Pro和DeepSeek-V4-Flash两个版本,两者均支持1M(一百万)的超长上下文长度。“从即日起,1M上下文将成为DeepSeek所有官方服务的标准配置。”
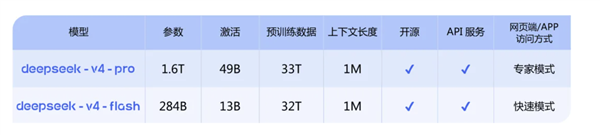
DeepSeek-V4-Pro的核心亮点在于其Agent能力的显著增强。在Agentic Coding评测中,V4-Pro已达到当前开源模型的顶尖水平。目前,DeepSeek-V4已在公司内部作为Agentic Coding模型投入使用,据内部反馈,其使用体验优于Sonnet 4.5,交付质量接近Opus 4.6的非思考模式,但与Opus 4.6的思考模式仍存在一定差距。
在世界知识评估方面,DeepSeek-V4-Pro大幅领先其他开源模型,仅次于闭源模型Gemini-Pro-3.1。推理性能方面,该模型在数学、STEM、竞赛型代码等测评中表现出色,超越了当前所有已公开评测的开源模型,成绩比肩世界顶级闭源模型。
相较之下,DeepSeek-V4-Flash则被定位为“更快捷高效的经济之选”,其模型参数和激活量相对较小。
技术创新驱动长上下文与算力优化
DeepSeek-V4在模型结构上也带来了显著的创新。据称,该模型开创了一种全新的注意力机制,通过在token维度进行压缩,并结合DSA稀疏注意力(DeepSeek Sparse Attention)技术,实现了对长上下文的强大支持。相较于传统方法,该机制大幅降低了对计算资源和显存的需求。
值得注意的是,深度求索在其DeepSeek-V4的技术报告中,罕见地同时提到了华为昇腾和英伟达:“我们在英伟达GPU和华为昇腾NPU平台上验证了细粒度EP(专家并行)方案。”这一表述显示了其在多硬件平台上的兼容性与优化能力。

深度求索表示,受限于当前高端算力的供应,DeepSeek-V4-Pro的服务吞吐量目前十分有限。预计随着下半年昇腾950超节点的大规模上市,Pro版本的价格有望大幅下调。
DeepSeek-V4在Agent能力方面的提升也尤为突出,通过对Claude Code、OpenClaw、OpenCode、CodeBuddy等主流Agent的适配与优化,在代码任务和文档生成任务上均实现了性能的提升。
技术演进与市场预热
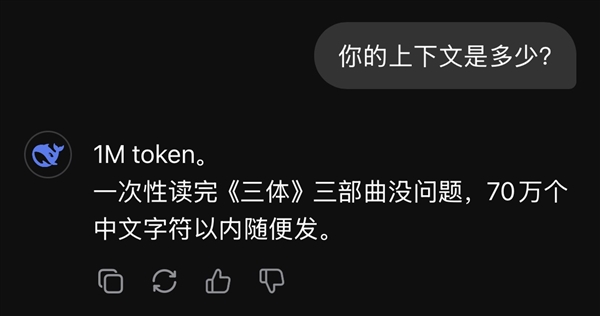
早在今年1月,DeepSeek-V4的部分技术创新点已通过“剧透”的方式提前显现。2月11日,DeepSeek的App端和网页端已悄然开始了重大升级的灰度测试。测试用户发现,模型的上下文窗口长度已增至1M token,足以“一次性读完《三体》三部曲”,并支持70万个中文字符的输入。此外,该版本模型的知识库截止时间更新至2025年5月。
在此之前,深度求索还罕见地连续发布了两篇技术论文,公司创始人梁文锋均参与了署名。其中一篇论文公开了mHC(Manifold-Constrained Hyper-Connections,流形约束超连接)技术,有效解决了大规模模型训练中的稳定性问题。另一篇论文则提出了名为Engram(条件记忆)的全新模块,其核心创新在于实现了适配超长上下文场景的“存算分离”。DeepSeek的实测数据显示,即使将100B(千亿)参数的Engram表挂载到CPU内存,相比纯GPU推理,吞吐量的下降幅度不足3%。
野村证券在一份研报中预测,V4将融合mHC和Engram技术路径,其技术突破有望有效打破“芯片墙”与“内存墙”的瓶颈。
据悉,DeepSeek的V系列是其通用大模型的主线迭代版本,擅长百科、写作、代码生成等常规任务,并具备快速响应的特点。2024年,DeepSeek-V1、V2、V3分别在上半年、年中和年末发布。而R系列则专注于推理增强,适用于数学、物理、逻辑谜题等需要分步思考的任务,并会展示详细的“思维链”。去年1月22日,DeepSeek-R1的相关论文已发布。
从DeepSeek的迭代进展来看,V系列去年经历了多次小版本升级,包括DeepSeek-V3-0324、DeepSeek-V3.1、DeepSeek-V3.1-Terminus,以及实验性版本DeepSeek-V3.2-Exp和正式版DeepSeek-V3.2及其Special版本。
值得关注的是,DeepSeek目前仍专注于纯文本和语音交互,尚未上线多模态能力。
此前,在与灰度测试版DeepSeek的对话中,其表示自身不具备“原生”的多模态理解能力,并且并没有一个具体的版本号(如V4或R1)来标识此次更新。

AI产品经理张亮认为,“要实现AGI,AI大模型必然会走向多模态融合,这是行业共识。多模态能力对DeepSeek而言将是不可或缺的,未来不仅要理解文本,还需要理解图像、视频乃至物理事件。”
新一代AI模型浪潮下的行业洗牌与生态位争夺
深度求索在DeepSeek-V4的官宣文稿结尾引用了《荀子·非十二子》中的“不诱于誉,不恐于诽,率道而行,端然正己”,似乎是在回应近几个月来围绕DeepSeek-V4的种种传言,包括“跳票”、人才流失、融资需求以及“去CUDA化”等。今日,《财经》杂志报道称,DeepSeek正计划融资18亿美元,投资方包括阿里和腾讯。
DeepSeek-V4的发布是否会引发行业新一轮洗牌?张亮表示,关键在于DeepSeek-V4在范式和代际上是否有重大提升,并以去年DeepSeek-R1在思维链和推理成本上的显著进步为例。然而,IDC中国研究总监卢言霞认为,DeepSeek-V4“谈不上会对市场格局带来大的洗牌,因为DeepSeek已经是数一数二的玩家了。”
此前,卢言霞指出,面对DeepSeek-V4,国内几家大厂“一定会有压力”。她解释道,DeepSeek作为开源模型,当前企业用户倾向于私有化部署,因此开源模型具有优势。如果DeepSeek能持续保持技术领先,有望成为事实上的Top1大模型。
业内人士也普遍认为,随着模型能力的上限不断逼近以及迭代速度的加快,各厂商如何结合自身优势,借势模型能力的提升来巩固生态位,将是下半场竞争的核心。
回顾2025年初,DeepSeek凭借其开源和低成本策略,成功打破了原有的市场格局,给科技巨头和头部初创模型厂商带来了显著压力。而2026年,则被视为中国AI模型产品发展的“大年”。
2月份,受DeepSeek-V4即将发布的传言影响,国内多家科技巨头趁春节期间再次发起流量入口的竞争。在营销投入的推动下,AI应用得到普及,豆包、元宝、千问以及DeepSeek均成功跻身“月活跃用户(MAU)亿级俱乐部”。同时,在产品层面,字节跳动也推出了视频生成模型Seedance。
DeepSeek-V4的出现,特别是其在长上下文、Agent能力和效率上的突破,预示着大模型技术正在朝着更强大、更普惠的方向发展。虽然短期内可能不会引发颠覆性的市场洗牌,但其持续的技术创新和开源策略,无疑将进一步加剧行业内的竞争,并促使更多企业和开发者拥抱这一变革,加速AI技术的落地应用。
AI模型技术加速迭代,上下文与Agent能力成焦点
近期,人工智能领域模型技术呈现出爆发式增长,多家科技公司密集发布新一代大模型,引发行业广泛关注。2月14日,豆包大模型2.0正式发布;除夕夜,阿里开源了新一代千问Qwen3.5模型。几乎同一时间,Kimi K2.5、GLM-5、MiniMax M2.5等模型也相继问世。本月,Qwen3.6-Plus、Xiaomi MiMo-V2.5、Hy3 preview等模型也陆续面世,预示着大模型技术谱系的加速扩展。
技术谱系加速扩展,上下文与Agent能力备受瞩目
自ChatGPT引爆此轮人工智能浪潮以来,产业创新迭代速度惊人。各头部厂商正持续刷新各方向的SOTA(state-of-the-art,当前最高水平),并加速推动技术谱系的扩展。其中,上下文(Context)和Agent能力在近期受到了特别的关注。
在上下文能力方面,从行业进展来看,谷歌Gemini系列率先于2024年初支持百万级超长上下文,随后在今年2月发布的Claude Opus 4.6也实现了这一能力。2月初,腾讯首席AI科学家姚顺雨团队的研究指出,让大模型学会从上下文中学习比想象中更困难,即便抹平上下文信息差,模型也未必能解决问题,这表明模型在上下文利用方面仍存在显著的能力短板。
Agent方面,开源AI智能体OpenClaw“龙虾”凭借其现象级表现,虽然并非面向普通消费者,但极大地推动了智能体的普及。英特尔中国区技术部总经理高宇表示,“‘龙虾’所带来的智能体的技术革命是不可逆转的。”
Skills(技能)同样是当前热点。Agent Skills通过元数据、可配置脚本、执行模板和详细说明等构成,支持复杂工作流的打包与复用。其关键优势在于可控性,通过结构化能力模块与思维链编排机制,使大模型具备可控、可复用、可持续优化的研究执行能力,并已应用于智能搜索、视频快剪、游戏辅助、安全护栏等多个垂类场景。金融科技服务商进门的CTO姜锐锋认为,Skills将推动AI应用从通用聊天走向领域专家,通过将特定工作流程固化为可复用的模块,解决了通用模型“懂道理却不会按规矩干活”的核心痛点,将行业竞争壁垒从比拼基础模型大小转向比拼高质量、专业化Skills生态的构建。
DeepSeek在多领域“出圈”,赋能千行百业
当前,DeepSeek在多个领域展现出了强大的能力,并获得了广泛的应用。DeepSeek-V3上线后,DeepSeek-R1在去年春节前夕发布,引发全球关注。随后,科技公司率先拥抱DeepSeek,三大运营商、阿里、腾讯、字节、百度等旗下的云平台和应用端产品纷纷接入。各地政府和央国企也加速适配DeepSeek。
从垂类应用视角来看,姜锐锋指出,DeepSeek对于投研行业的适配度很高,其公司AI产品方案采用多模型协同,利用DeepSeek进行语义路由,匹配投研思维链,Kimi k2.5调用投研工具,豆包模型裁剪工具返回结果,最终由DeepSeek汇总输出,兼顾了成本与效率。
野村证券研报也曾指出,预计mHC和Engram的结合将使DeepSeek-V4更适合医疗、法律、金融等知识密集型领域的行业大模型训练。
在软件领域,多家A股软件公司已将DeepSeek作为其工作目标和方法的关联核心。腾讯元宝在去年12月发布的报告显示,自接入DeepSeek以来,用户规模逐步扩大,日使用量较年初增长超过100倍,目前元宝在国内原生AI应用中处于前三位置。
硬件方面,一体机品类因DeepSeek而走红。截至去年2月底,已有超过60家企业宣布基于DeepSeek推出一体机,内置不同尺寸的DeepSeek模型。去年年中,OPPO方面透露,其人工智能助手“小布助手”是全球接入DeepSeek设备量最大的手机智能助理。
开发者群体对DeepSeek-V4也充满期待。张亮提到,开发者关注新模型在参数维度上的全面性。他指出,千问模型参数覆盖范围广,即使低配GPU也能找到对应的小模型进行部署。然而,DeepSeek目前缺乏这样的小模型参数,对于中小企业和开发者不够友好。此前,DeepSeek凭借开源策略和极致性价比在全球建立了扎实口碑。野村证券分析,DeepSeek-V4的核心价值在于通过底层架构创新推动AI应用商业化落地,赋能本土算力硬件与AI应用双向发展。

总体而言,近期AI模型技术的快速发展,特别是上下文长度的突破和Agent能力的强化,预示着AI应用正朝着更专业化、可控化和高效化的方向迈进。DeepSeek等模型的广泛应用,也展现了AI技术在赋能千行百业方面的巨大潜力。