DeepSeek V4 登场:百万级上下文与成本优化重塑大模型格局
经过一年半的潜心研发,DeepSeek 今日正式发布了其最新的大模型 DeepSeek V4 系列。此次更新不仅在性能上展现了显著的飞跃,更在上下文长度和成本控制方面带来了突破性进展,预示着开源大模型正在加速追赶甚至在某些维度超越顶尖闭源模型。

DeepSeek V4 系列共推出两款模型:DeepSeek-V4-Flash 和 DeepSeek-V4-Pro。其中,V4-Pro 在性能上已能与 Claude Opus 4.6、GPT 5.4、Gemini 3.1 Pro 等行业顶尖闭源模型展开全面竞争,在多项关键指标上实现了“五五开”的局面。在代码生成等生产力场景下,V4-Pro 的表现也位居前列,仅次于 Claude Opus 4.6,远超同等性能的友商模型。
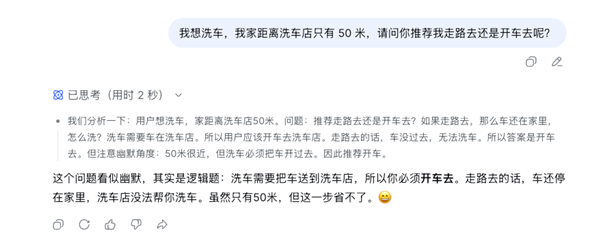
相较于此前,V4-Pro 的价格策略尤为引人注目。尽管价格较上一代有所上涨,但与同等性能的闭源模型相比,其成本优势依然显著。例如,百万 token 输出的费用约为 24 元,而 Claude Sonnet 4.6 接近 100 元,价格优势高达四分之一。DeepSeek 表示,模型价格的上涨是暂时的,随着华为等硬件的到位,未来价格有望进一步下探,体现了其一贯的“高性价比”策略。

DeepSeek V4 系列最令人瞩目的升级之一,便是其对百万 token 上下文长度的支持。这一特性对于 Agent 类工具的发展至关重要。在 Agent 的工作流程中,海量的对话历史需要被有效记忆和处理,长上下文能力意味着模型能够更好地理解和记住复杂的指令及细节,避免信息丢失或误解。
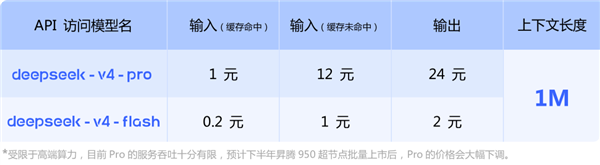
这一点的重要性在近期的一些事件中得到了体现。此前,由于模型上下文长度不足,导致 AI 在处理邮件时遗漏了关键信息,引发了安全问题。DeepSeek V4 系列将百万 token 上下文作为标配,无论是 Pro 还是 Flash 版本,都能轻松应对此类挑战,极大地提升了模型的“记忆”和“理解”能力。在实际测试中,DeepSeek V4 能够快速准确地在文本中找出异常内容,展现了其强大的长文本处理能力。

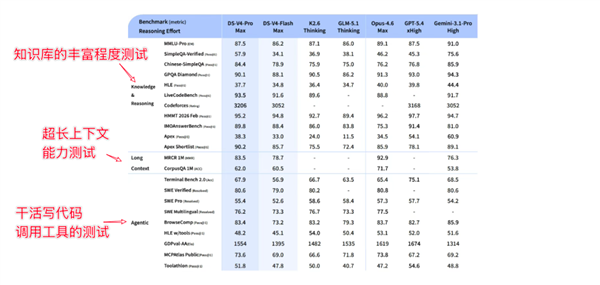
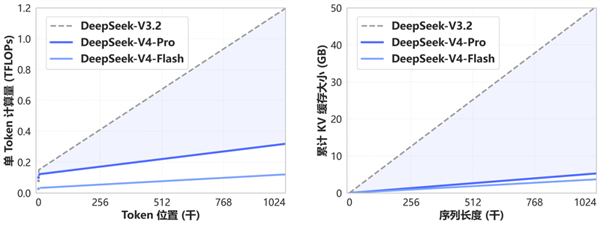
更令人惊喜的是,DeepSeek V4 在实现百万 token 上下文的同时,在成本控制上取得了显著进展。传统 Transformer 架构在处理长上下文时,KV Cache 的增大导致推理成本急剧上升。DeepSeek V4 通过技术优化,在处理相同长度的上下文时,V4-Pro 的生成 token 计算量仅为原来的四分之一,而用于记忆前文的 KV Cache 更是减少至原来的十分之一。这意味着在提供强大长文本能力的同时,其运行成本大幅降低,极大地提升了模型的经济性。
DeepSeek V4 系列的发布,不仅是 DeepSeek 自身技术实力的全面展示,也标志着开源大模型在核心能力上达到了新的高度。其在性能、上下文长度和成本优化上的平衡,为开发者和企业提供了更具吸引力的选择,有望加速大模型在更多场景下的落地和应用。
DeepSeek V4:技术革新与生态布局下的AI新篇章
经过一年半的沉淀,DeepSeek 终于推出了其最新的大模型版本 V4。此次更新在成本控制、性能优化以及生态合作方面展现了显著的进步,尤其是在底层技术和硬件适配上进行了深度探索。
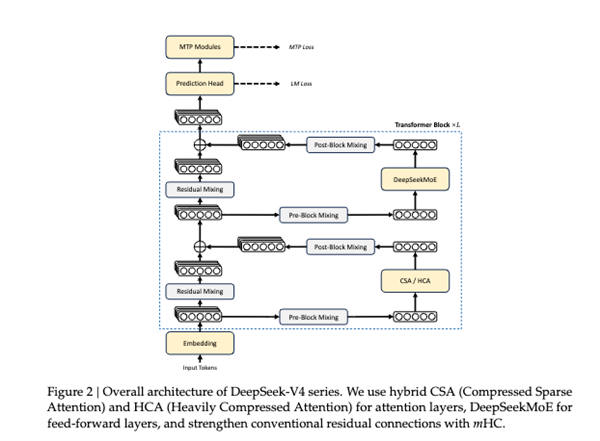
DeepSeek V4 能够实现成本的显著降低,关键在于其引入了一套全新的注意力机制——Hybrid Attention。这一机制巧妙地融合了压缩稀疏注意力(CSA)和重度压缩注意力(HCA)这两种技术。CSA 类似于为模型提供一个“目录”,而 HCA 则负责为目录中的“章节”生成“摘要”。通过这种方式,模型在处理信息时,核心计算压力得以大幅缓解。此外,为了保证长文本的稳定性,DeepSeek V4 沿用了去年的 mHC 技术,并引入了 Muon 优化器以提升模型参数的稳定性。
在底层技术和硬件适配方面,DeepSeek V4 也投入了大量精力。通过在英伟达和华为的 GPU 上测试其自研的 fine-grained EP,模型的推理速度得到了 1.50 至 1.73 倍的提升。更值得关注的是,DeepSeek V4 还集成了北大开源的 TileLang(Tile Language),这使得模型在一定程度上减少了对 NVIDIA CUDA 的依赖,为国产 AI 硬件生态的发展提供了新的可能。

尽管 DeepSeek V4 在性能和成本上表现出色,但目前版本尚不支持多模态能力,即无法处理图像信息。这一点被认为是该版本的一个主要限制,也预示着多模态将是其下一代发展的重要方向。
除了在华为等国产芯片上的优化,DeepSeek V4 的发布也揭示了其在 AI 生态中的一些战略布局。在提及 Agent 能力优化时,DeepSeek 不仅列出了 Claude Code、OpenClaw 等知名产品,还包括了腾讯的 CodeBuddy。这或许与近期腾讯、阿里等公司洽谈投资 DeepSeek 的传闻不无关系,显示出 DeepSeek 在吸引投资和构建合作生态方面的积极动作。

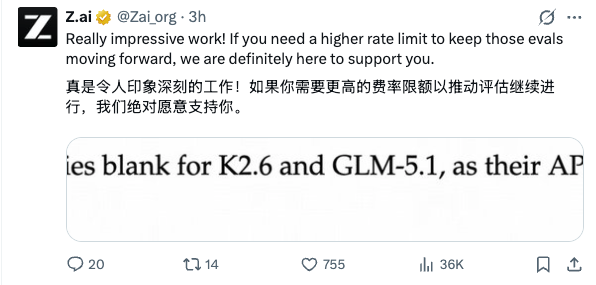
在与友商的对比测试中,DeepSeek V4 的研究人员在尝试获取 Kimi K2.6 和智谱 GLM-5.1 的 API 数据时遇到了繁忙的情况。智谱官方对此做出了积极回应,表示愿意提供高速率账号支持,这反映出国内大模型厂商之间在技术交流与合作上的开放态度。

DeepSeek 还针对硬件厂商提出建议,强调在设计 GPU 时应注重“算力与通信”的比例,以实现更高效的能耗比,这对于推动 AI 硬件的合理发展具有指导意义。

DeepSeek 官方坦承,与当前世界最先进的闭源旗舰模型相比,能力上仍存在 3 到 6 个月的差距。然而,其在开源社区的持续发力,尤其是在去年推出的 R1 版本,曾引领了大推理时代。而 DeepSeek V4 通过与华为等国产芯片厂商的合作,不仅展示了其自身的技术实力,更彰显了中国在 AI 领域打破技术垄断的决心与潜力。
过去一段时间,DeepSeek 经历了不少关于人才流失、国产芯片适配困难的讨论和质疑,甚至出现了“DeepSeek 新版本下周更新”的网络笑话。但 DeepSeek V4 的推出,用实力回应了这些声音,再次证明了其在开源大模型领域的活跃度和影响力。
DeepSeek 官方在发布会上引用了“不诱于誉,不恐于诽,率道而行,端然正己”的十六字真言,这既是对过往争议的回应,也是对其未来发展方向的坚定表达。DeepSeek V4 的诞生,不仅标志着其自身技术的进步,更是在推动国产 AI 产业生态发展、实现技术自主可控的道路上迈出了坚实一步。

DeepSeek V4 的发布,展现了开源大模型在性能优化和成本控制上的持续突破,特别是在国产硬件适配方面的努力,预示着 AI 领域正在形成更加多元和自主的生态体系。尽管在多模态等前沿领域仍有提升空间,但其务实的研发路径和对生态的积极投入,使其成为观察中国 AI 发展不可忽视的一股重要力量。